Von der Ticket-Warteschlange zur stationären Verteilung
Autor:in
Zugehörigkeit
Markus Geuss
Fernfachhochschule Schweiz
TippLernziele
Lernziele
Nach diesem Tutorial …
kann ich erklären, was einen stochastischen Prozess zur Markovkette macht, und warum die sogenannte Gedächtnislosigkeit die entscheidende Eigenschaft ist.
bin ich in der Lage, aus einer Problembeschreibung die Zustandsmenge, das Übergangsdiagramm und die Übergangsmatrix \(P\) aufzustellen.
kann ich den Zustandsvektor \(q_t = q_0 \cdot P^t\) in R berechnen und interpretieren.
bin ich in der Lage, die stationäre Verteilung \(\pi\) als lineares Gleichungssystem in R zu lösen und betriebswirtschaftlich zu interpretieren.
kann ich die Eigenschaften irreduzibel und aperiodisch an einem Übergangsdiagramm erkennen und erklären, warum sie für die Konvergenz notwendig sind.
bin ich in der Lage, den Übergang von diskreter zu kontinuierlicher Zeit zu beschreiben und Übergangsraten von Übergangswahrscheinlichkeiten zu unterscheiden.
kann ich das Gleichgewicht einer kontinuierlichen Markovkette mit R berechnen und als Verfügbarkeit oder mittlere Aufenthaltsdauer interpretieren.
bin ich in der Lage, ein einfaches M/M/1-Warteschlangenmodell aufzustellen, den stationären Zustand zu berechnen und die Formel von Little anzuwenden.
Dieses Tutorial behandelt Markovketten — eines der nützlichsten stochastischen Modelle in Informatik und Wirtschaftsinformatik. Das Besondere: Wir werden kein einziges Konzept einführen, bevor wir nicht verstanden haben, warum wir es brauchen. Die Theorie folgt dem Problem, nicht umgekehrt.
WichtigArbeitsmodus für dieses Tutorial
Jedes Kapitel beginnt mit einer Frage aus der Praxis. Erst wenn klar ist, was wir eigentlich wissen wollen, holen wir uns die Theorie dazu.
Die gleiche Situation — ein IT-Helpdesk mit vier Ticket-Zuständen — zieht sich durch das gesamte Tutorial. Was in Kapitel 2 per Hand gerechnet wird, simulieren wir in Kapitel 3 in R.
R ist Werkzeug, nicht Selbstzweck. Wir verstehen zuerst, was eine Berechnung bedeutet — dann überlassen wir sie dem Computer.
Zufall mit Gedächtnis — oder ohne?
Es ist Dienstagmittag. Der IT-Helpdesk eines mittelständischen Unternehmens hat 340 offene Tickets. Die Service-Level-Vereinbarung mit den internen Kunden lautet: 90 % aller Tickets müssen innerhalb von 24 Stunden gelöst sein. Aktuell sind es 71 %. Die Teamleiterin will wissen: Reichen die fünf verfügbaren Agents bis Feierabend, oder muss sie jetzt reagieren?
Um diese Frage zu beantworten, braucht sie kein Bauchgefühl — sie braucht ein Modell, das beschreibt, wie sich Tickets im Laufe des Tages bewegen. Ein Ticket befindet sich zu jedem Zeitpunkt in genau einem von vier Zuständen:
Zustand
Bedeutung
0 — Offen
Ticket eingegangen, noch niemand zugewiesen
1 — In Bearbeitung
Ein Agent arbeitet daran
2 — Gelöst
Problem behoben, Ticket geschlossen
3 — Eskaliert
An zweite Supportebene übergeben
Im Verlauf des Tages wechseln Tickets zwischen diesen Zuständen. Manche Tickets werden gelöst und Stunden später wieder geöffnet, weil das Problem zurückgekehrt ist. Manche eskalierten Tickets werden direkt gelöst, ohne den normalen Bearbeitungsweg zu durchlaufen.
Die Teamleiterin will in zwei Stunden wissen, wie viele Tickets dann noch offen sein werden — nicht für ein einzelnes Ticket, sondern für den gesamten Bestand. Was muss sie über das System wissen, um das berechnen zu können? Reicht der aktuelle Zustand jedes Tickets, oder braucht sie auch die Vorgeschichte — wie lange ein Ticket schon offen ist, wie oft es bereits bearbeitet wurde?
Das ist keine triviale Frage. In der Praxis ist der Unterschied enorm: Wer die gesamte Vorgeschichte jedes Tickets braucht, muss sie speichern, mitschleppen und auswerten — für 340 Tickets, über Wochen, mit wachsender Komplexität. Wer dagegen zeigen kann, dass nur der aktuelle Zustand zählt, erhält ein Modell, das mit einer einzigen 4×4-Matrix auskommt und trotzdem erstaunlich genaue Vorhersagen liefert.
Die entscheidende Vereinfachung
In vielen realen Systemen — Helpdesks, Produktionsprozessen, Webseitennavigation, Kreditrisikobewertung — lässt sich beobachten, dass die Zukunft eines Systems vom aktuellen Zustand abhängt, aber kaum noch davon, wie dieser Zustand erreicht wurde. Ein Ticket, das gerade eskaliert wurde, hat in der Praxis dieselbe Lösungswahrscheinlichkeit, egal ob es zuvor zweimal oder zwölfmal den Bearbeiter gewechselt hat — weil mit der Eskalation ein neues Team und ein neuer Prozess übernehmen.
Das bedeutet: Für solche Systeme reicht der aktuelle Zustand als vollständige Beschreibung der Situation. Die Vergangenheit ist eingepreist — sie hat den aktuellen Zustand hervorgebracht, aber sie enthält keine zusätzliche Information, die unsere Vorhersage verbessern würde. Wir beschränken uns im Folgenden auf genau diese Klasse von Systemen.
TippMarkov-Eigenschaft (Gedächtnislosigkeit)
Ein stochastischer Prozess \((X_t)_{t \in \mathbb{N}_0}\) heisst Markovkette, wenn für alle Zeitpunkte \(t\) und alle Zustände gilt:
Der nächste Zustand hängt ausschliesslich vom aktuellen Zustand ab — nicht davon, wie er erreicht wurde. Man nennt diese Eigenschaft Gedächtnislosigkeit.
Mit dieser Einschränkung kaufen wir uns etwas Entscheidendes: Statt die gesamte Verlaufsgeschichte jedes Tickets zu verwalten, genügt ein einziger Wert pro Ticket — der aktuelle Zustand. Und statt eines wachsenden Datenbergs reicht eine kompakte Matrix, um das Verhalten des gesamten Systems zu beschreiben. Was diese Matrix ist und wie wir damit rechnen, ist das Thema des nächsten Kapitels.
Verständnisfrage 1: Markov oder nicht?
Ein Ticket befindet sich gerade im Zustand «In Bearbeitung».
Welche der folgenden Aussagen ist mit der Markov-Eigenschaft vereinbar?
a) «Die Wahrscheinlichkeit, dass das Ticket heute noch gelöst wird,
hängt davon ab, wie viele Stunden es bereits in Bearbeitung ist.»
b) «Die Wahrscheinlichkeit, dass das Ticket heute noch gelöst wird,
ist für alle Tickets im Zustand ‹In Bearbeitung› gleich —
unabhängig davon, was vorher passiert ist.»
c) «Tickets, die zuvor schon einmal eskaliert waren, werden aus dem
Zustand ‹In Bearbeitung› seltener gelöst als andere.»
d) «Die Lösungswahrscheinlichkeit steigt, je mehr Bearbeiterwechsel
ein Ticket hinter sich hat.»
Antwort anzeigen
Richtige Antwort: b) Nur Aussage b) ist mit der
Markov-Eigenschaft vereinbar. Sie besagt genau das, was wir
definiert haben: Der nächste Zustand hängt ausschliesslich vom
aktuellen Zustand ab. Die Aussagen a), c) und d) beziehen sich alle
auf die Vorgeschichte des Tickets — wie lange es schon bearbeitet
wird, ob es eskaliert war, wie viele Wechsel es gab. Genau das
schliesst die Markov-Eigenschaft aus.
Was wir jetzt wissen — und was noch fehlt
Wir haben die zentrale Modellierungsentscheidung getroffen: Der nächste Zustand hängt nur vom aktuellen ab. Was wir noch nicht haben, ist ein konkretes Werkzeug — eine Möglichkeit, die Übergänge zwischen den Zuständen systematisch zu beschreiben und damit zu rechnen.
Die Teamleiterin braucht Zahlen: Wie wahrscheinlich ist es, dass ein offenes Ticket morgen in Bearbeitung ist? Wie wahrscheinlich, dass ein eskaliertes direkt gelöst wird? Diese Fragen führen uns zur Übergangsmatrix.
Wie sich Tickets bewegen — Übergänge, Tabellen, Diagramme
Die Teamleiterin sitzt vor den Logs des letzten Quartals. Sie hat drei Fragen, die sie wirklich beschäftigen:
Kurzfristig: Von den 340 Tickets, die heute offen sind — wie viele werden morgen noch offen sein, übermorgen, in einer Woche?
Mittelfristig: Wann kippt die SLA-Quote wieder über 90 %, wenn das aktuelle Bearbeitungstempo anhält?
Langfristig: Wohin konvergiert das System, wenn nichts am Prozess geändert wird — und wie viele Agents braucht der Helpdesk dauerhaft, um diesen Zustand zu bewältigen?
Bevor wir die Logs öffnen, lohnt es sich, diese Fragen zu analysieren: Was müsste man eigentlich wissen, um sie beantworten zu können?
Was wir wissen müssen
Nehmen wir die kurzfristige Frage. Ein Ticket ist heute «Offen». Damit wir wissen, mit welcher Wahrscheinlichkeit es morgen «In Bearbeitung» ist, brauchen wir eine einzige Zahl — die Wahrscheinlichkeit des Übergangs von «Offen» nach «In Bearbeitung».
Aber es gibt vier Zustände. Für jeden der vier Ausgangszustände gibt es vier mögliche Folgezustände — das sind 4 × 4 = 16 Übergangswahrscheinlichkeiten. Wenn wir diese 16 Zahlen kennen, können wir für jedes Ticket in jedem Zustand angeben, wie wahrscheinlich jeder mögliche nächste Zustand ist.
Die mittelfristige Frage ist dieselbe Logik — nur wiederholt: Wir wenden dieselben 16 Zahlen mehrfach an, Schritt für Schritt. Und die langfristige Frage fragt, wohin diese wiederholte Anwendung schliesslich führt.
Alle drei Fragen brauchen dieselbe Grundlage: die 16 Übergangs- wahrscheinlichkeiten zwischen den vier Zuständen. Wie würdest du diese 16 Zahlen so anordnen, dass auf einen Blick erkennbar ist, welche Übergänge häufig, selten oder unmöglich sind — und dass man damit rechnen kann?
Die naheliegende Antwort ist eine Tabelle: Ausgangszustände in den Zeilen, Folgezustände in den Spalten. Genau diese Tabelle werden wir jetzt aus den Logs herausarbeiten.
Ein Blick in die Logs
Die IT-Abteilung exportiert die Ticket-Logs des letzten Quartals. Jede Zeile steht für einen echten Zustandswechsel — protokolliert mit Zeitstempel, sobald jemand das Ticket angefasst hat:
Da nur echte Zustandswechsel protokolliert werden, taucht kein Zustand zweimal hintereinander auf — ein Ticket, das einen Tag lang offen bleibt ohne dass jemand es anfasst, erscheint in dieser Zeit nicht im Log.
Schau dir die drei Verläufe von oben nach unten an. Welche konkreten Übergänge — also welche Paare (Zustand in Zeile \(t\), Zustand in Zeile \(t+1\)) desselben Tickets — sind in dieser Vorschau sichtbar? Notiere sie kurz. Welcher Übergang, den du grundsätzlich für möglich hältst, fehlt hier vollständig?
Um diese Frage systematisch zu beantworten — nicht nur für drei, sondern für alle 500 Tickets — brauchen wir eine strukturierte Auswertung. Wir bilden für jedes Ticket Paare aus aufeinanderfolgenden Zeilen: Zeile \(t\) wird zum Ausgangszustand, Zeile \(t+1\) zum Folgezustand.
Zwei Dinge fallen sofort auf: Kein Ticket wechselt direkt von «Offen» nach «Gelöst» oder «Eskaliert». Und kein Eintrag hat denselben Zustand in beiden Spalten — da wir nur echte Wechsel protokollieren, gibt es keine Selbstübergänge.
Die Darstellung ist aber noch unbequem: Für jeden Ausgangszustand stehen die Ziele verstreut über mehrere Zeilen. Erinnern wir uns an die Kreuztabelle im Fussball.
Wie müsste man die Tabelle umstrukturieren, damit man für jeden Ausgangszustand auf einen Blick sieht, wohin Tickets von dort aus wechseln — und wohin nicht?
Eine Tabelle für alle Übergänge auf einmal
Wir stellen die Ausgangszustände in die Zeilen und die Zielzustände in die Spalten:
Tabelle 2: Beobachtete Übergangshäufigkeiten. Zeilen: Ausgangszustand, Spalten: Zielzustand. Die Diagonale ist überall null.
Offen
In Bearbeitung
Gelöst
Eskaliert
Offen
0
577
0
0
In Bearbeitung
0
0
504
168
Gelöst
77
11
0
0
Eskaliert
0
84
84
0
Die Nullen auf der Diagonalen bestätigen: kein Zustand geht in sich selbst über. Die übrigen Nullen zeigen, welche Wechsel im System strukturell nicht vorkommen. Aber die absoluten Zahlen haben noch ein Problem — kannst du es benennen?
«Gelöst» hat die höchsten Werte in seiner Zeile, weil Tickets diesen Zustand schlicht am häufigsten besuchen. «Eskaliert» hat niedrige Werte, weil es selten erreicht wird. Die Häufigkeiten machen die Ausgangszustände untereinander nicht vergleichbar.
Von Häufigkeiten zu Wahrscheinlichkeiten
Die Lösung liegt nahe: Wir teilen jede Zeile durch ihre Zeilensumme. Damit wird jeder Eintrag zur relativen Häufigkeit — dem Anteil aller Abgänge aus diesem Zustand, der in den jeweiligen Folgezustand führt.
Tabelle 3: Geschätzte Übergangswahrscheinlichkeiten. Jede Zeile summiert auf 1, die Diagonale bleibt null.
Offen
In Bearbeitung
Gelöst
Eskaliert
Offen
0.00
1.00
0.00
0.00
In Bearbeitung
0.00
0.00
0.75
0.25
Gelöst
0.88
0.12
0.00
0.00
Eskaliert
0.00
0.50
0.50
0.00
Schau dir jede Zeile an. Alle Einträge summieren sich auf 1 — das ist keine Zufälligkeit, sondern eine direkte Konsequenz der Normierung. Jede Zeile beschreibt vollständig, was mit einem Ticket in diesem Zustand beim nächsten Ereignis passieren kann. Nichts bleibt offen, keine Wahrscheinlichkeit geht verloren.
Diese Tabelle hat einen Namen — und mit dem Namen kommen alle Werkzeuge der Stochastik.
TippÜbergangsmatrix
Die Übergangsmatrix\(P\) einer Markovkette mit \(n\) Zuständen ist eine \(n \times n\)-Matrix. Der Eintrag \(p_{ij}\) gibt die Wahrscheinlichkeit an, in einem Schritt vom Zustand \(i\) in den Zustand \(j\) zu wechseln:
\[p_{ij} = \Pr[X_{t+1} = j \mid X_t = i]\]
Da aus jedem Zustand mit Sicherheit irgendein Übergang stattfindet, summiert jede Zeile auf 1:
\[\sum_{j=1}^{n} p_{ij} = 1 \qquad \text{für alle } i\]
Eine Matrix mit dieser Eigenschaft heisst stochastische Matrix.
Die Übergangsmatrix in R
Die Tabelle von oben überführen wir jetzt in ein R-Objekt, mit dem wir in den nächsten Kapiteln rechnen werden:
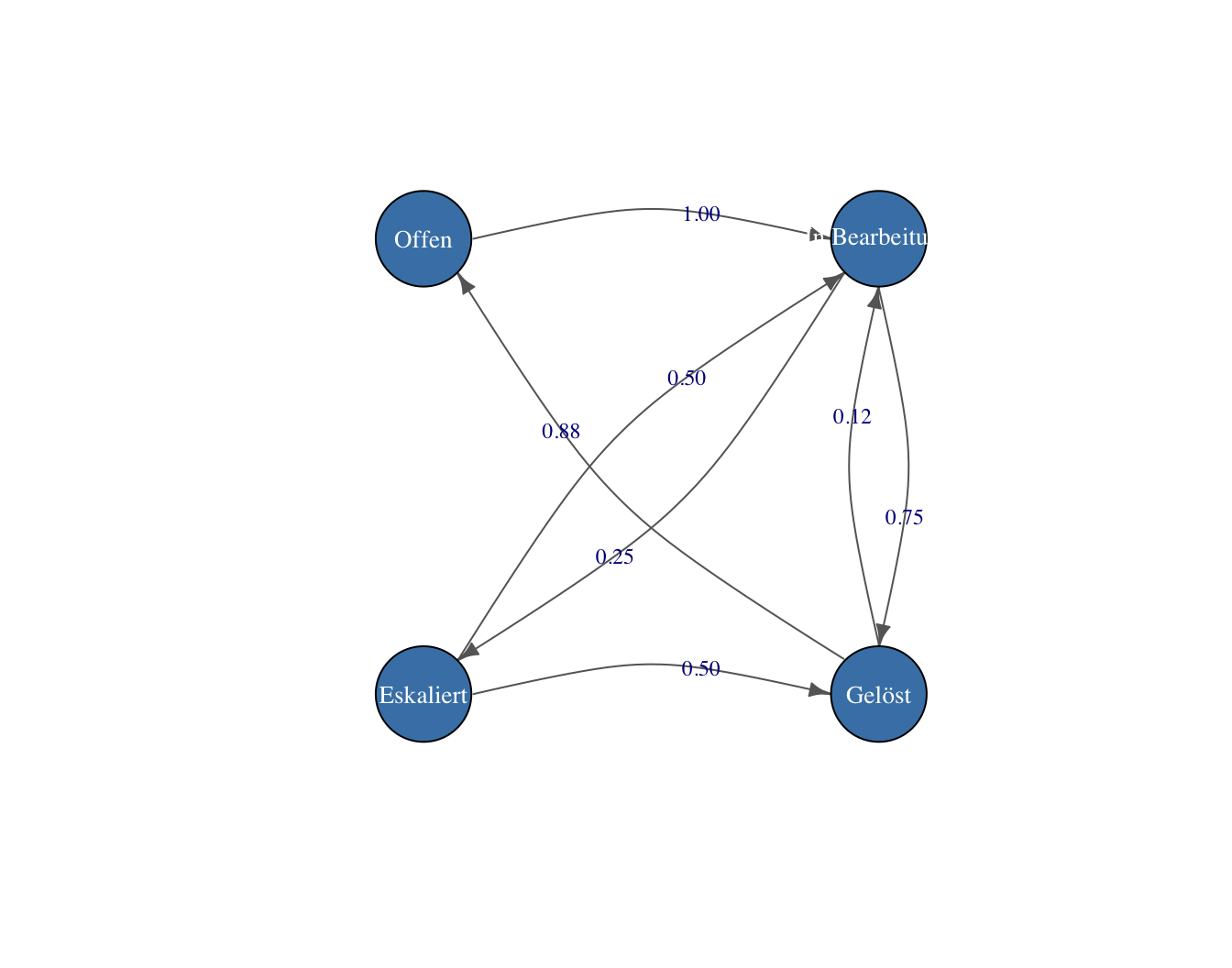
Abbildung 1: Übergangsdiagramm des Helpdesk-Modells. Keine Schleifen, da der Log nur echte Zustandswechsel enthält.
Das Diagramm macht die Struktur des Systems mit einem Blick sichtbar: «Offen» hat nur einen Ausgang — jedes Ticket wird irgendwann zugewiesen. «Gelöst» hat zwei Ausgänge, weil ein kleiner Teil der Tickets nach der Lösung erneut geöffnet wird. Und «Eskaliert» führt nie zurück nach «Offen» — eskalierte Tickets werden immer direkt weiterbearbeitet oder gelöst, nie einfach zurückgestellt.
Verständnisfrage 2: Die Übergangsmatrix lesen
Die Teamleiterin schaut auf die Tabelle und fragt:
«Was sagt mir der Wert in der Zeile Eskaliert,
Spalte In Bearbeitung?»
a) 40 % aller Tickets werden irgendwann in Bearbeitung genommen,
bevor sie eskaliert werden.
b) Ein Ticket in Bearbeitung wird mit ca. 40 % Wahrscheinlichkeit
im nächsten Schritt eskaliert.
c) Ein eskaliertes Ticket wird mit ca. 40 % Wahrscheinlichkeit
beim nächsten Ereignis zurück in Bearbeitung gegeben.
d) 40 % der eskalierten Tickets wurden vorher mindestens einmal
in Bearbeitung genommen.
Antwort anzeigen
Richtige Antwort: c)
Die Zeile gibt den aktuellen Zustand an, die Spalte
den nächsten. Zeile «Eskaliert», Spalte «In Bearbeitung»
beschreibt den Übergang von eskaliert nach in Bearbeitung —
nicht umgekehrt. Antwort b) dreht die Leserichtung um.
Die Antworten a) und d) verwechseln einen einzelnen
Übergangsschritt mit einer Aussage über den gesamten
Ticket-Lebenszyklus.
Was wir jetzt haben — und was noch fehlt
Aus den Rohdaten haben wir durch Zählen, Normieren und Umstrukturieren eine Übergangsmatrix gebaut — kompakt, berechenbar, vollständig. Gerechnet haben wir damit aber noch nichts.
Die Teamleiterin will wissen, wie sich die aktuellen 340 Tickets morgen verteilen werden — nicht für ein einzelnes Ticket, sondern für den gesamten Bestand. Dafür reicht die Matrix allein nicht. Wir brauchen zusätzlich einen Startpunkt: Wie viele Tickets befinden sich heute in welchem Zustand? Das führt uns zum Zustandsvektor und zur Frage, wie man \(P\) damit verknüpft. Das ist das Thema des nächsten Kapitels.
Was passiert morgen? — Zustandsvektor und Matrixpotenz
Die Teamleiterin öffnet das Dashboard. Es ist Dienstagmorgen, 08:00 Uhr. Von den 340 aktiven Tickets befinden sich:
Zustand
Anzahl
Offen
120
In Bearbeitung
85
Gelöst
87
Eskaliert
48
Sie hat die Übergangsmatrix \(P\) aus den Logs der letzten drei Monate. Jetzt will sie wissen: Wie viele dieser Tickets werden morgen in welchem Zustand sein?
Ein Zustand — von Hand
Fangen wir mit einer konkreten Teilfrage an. Wie viele Tickets werden morgen «In Bearbeitung» sein?
Diese Tickets können aus vier Quellen kommen:
Heute offene Tickets, die zugewiesen werden: \(120 \times p_{\text{Offen} \to \text{InBe}}\)
Heute in Bearbeitung befindliche Tickets, die noch laufen: \(85 \times p_{\text{InBe} \to \text{InBe}}\)
Heute gelöste Tickets, die wiedereröffnet und zugewiesen werden: \(87 \times p_{\text{Gelöst} \to \text{InBe}}\)
Heute eskalierte Tickets, die zurückgegeben werden: \(48 \times p_{\text{Esk} \to \text{InBe}}\)
Code
# Heutiger Bestandn_heute <-c("Offen"=120, "In Bearbeitung"=85,"Gelöst"=87, "Eskaliert"=48)# Übergangswahrscheinlichkeiten in die Spalte "In Bearbeitung"p_nach_inbe <- P[, "In Bearbeitung"]p_nach_inbe
Offen In Bearbeitung Gelöst Eskaliert
1.000 0.000 0.125 0.500
Code
# Erwartete Anzahl "In Bearbeitung" morgensum(n_heute * p_nach_inbe)
[1] 154.875
Schau dir die Berechnung an: sum(n_heute * p_nach_inbe). Das ist eine gewichtete Summe — jede heutige Ticketanzahl wird mit der Wahrscheinlichkeit gewichtet, morgen «In Bearbeitung» zu sein. Wie würdest du dieselbe Rechnung für den Zustand «Gelöst» aufstellen? Und was fällt dir auf, wenn du beide Rechnungen nebeneinander siehst?
Alle Zustände auf einmal
Für jeden der vier Zielzustände brauchen wir dieselbe gewichtete Summe — nur mit einer anderen Spalte von \(P\). Das viermal separat zu rechnen wäre aufwendig. Aber es gibt eine kompaktere Schreibweise.
Wenn wir den heutigen Bestand als Zeilenvektor schreiben —
\[\mathbf{n}_0 = (120,\; 85,\; 87,\; 48)\]
— dann ist die gestrige Rechnung für «In Bearbeitung» nichts anderes als das Skalarprodukt von \(\mathbf{n}_0\) mit der zweiten Spalte von \(P\). Die Rechnung für alle vier Zielzustände gleichzeitig entspricht der Multiplikation des Zeilenvektors mit der gesamten Matrix \(P\):
\[\mathbf{n}_1 = \mathbf{n}_0 \cdot P\]
Das Ergebnis ist wieder ein Zeilenvektor — diesmal mit den erwarteten Ticketanzahlen von morgen.
Offen In Bearbeitung Gelöst Eskaliert
[1,] 76 155 88 21
Für weitere Tage wenden wir dieselbe Logik wiederholt an: \(\mathbf{n}_2 = \mathbf{n}_1 \cdot P\), und so weiter. Oder direkt: \(\mathbf{n}_t = \mathbf{n}_0 \cdot P^t\).
Bevor wir das formalisieren, lohnt es sich, die Rechnung mit relativen Anteilen statt absoluten Zahlen zu wiederholen — das macht die Vorhersagen unabhängig von der aktuellen Gesamtzahl der Tickets.
TippZustandsvektor
Der Zustandsvektor\(\mathbf{q}_t\) ist ein Zeilenvektor der Länge \(n\), dessen \(i\)-ter Eintrag die Wahrscheinlichkeit (bzw. den relativen Anteil) angibt, mit der sich das System zur Zeit \(t\) im Zustand \(i\) befindet:
\[(\mathbf{q}_t)_i = \Pr[X_t = i]\]
Die Einträge sind nichtnegativ und summieren sich auf 1. Ausgehend von einer Startverteilung \(\mathbf{q}_0\) gilt:
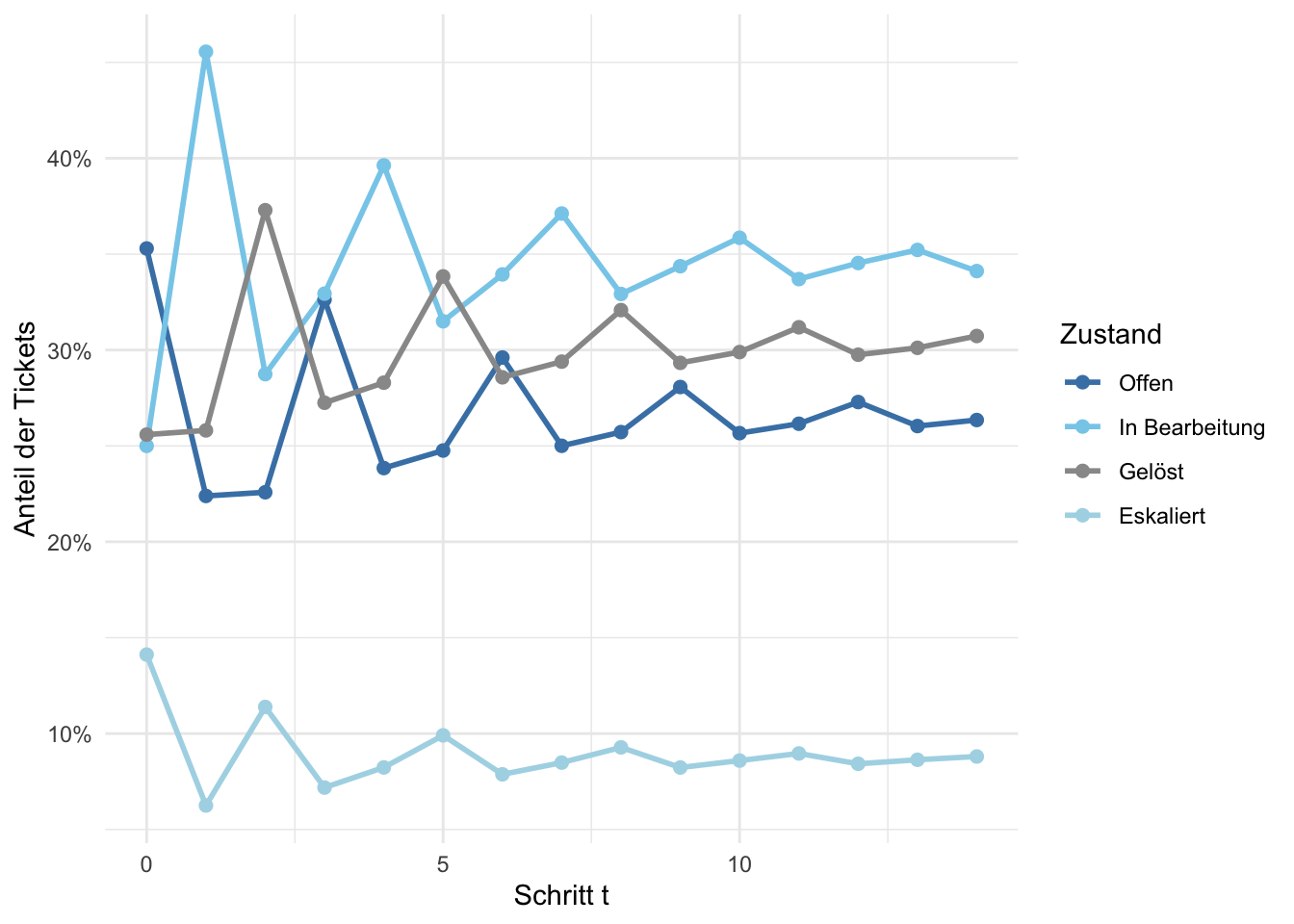
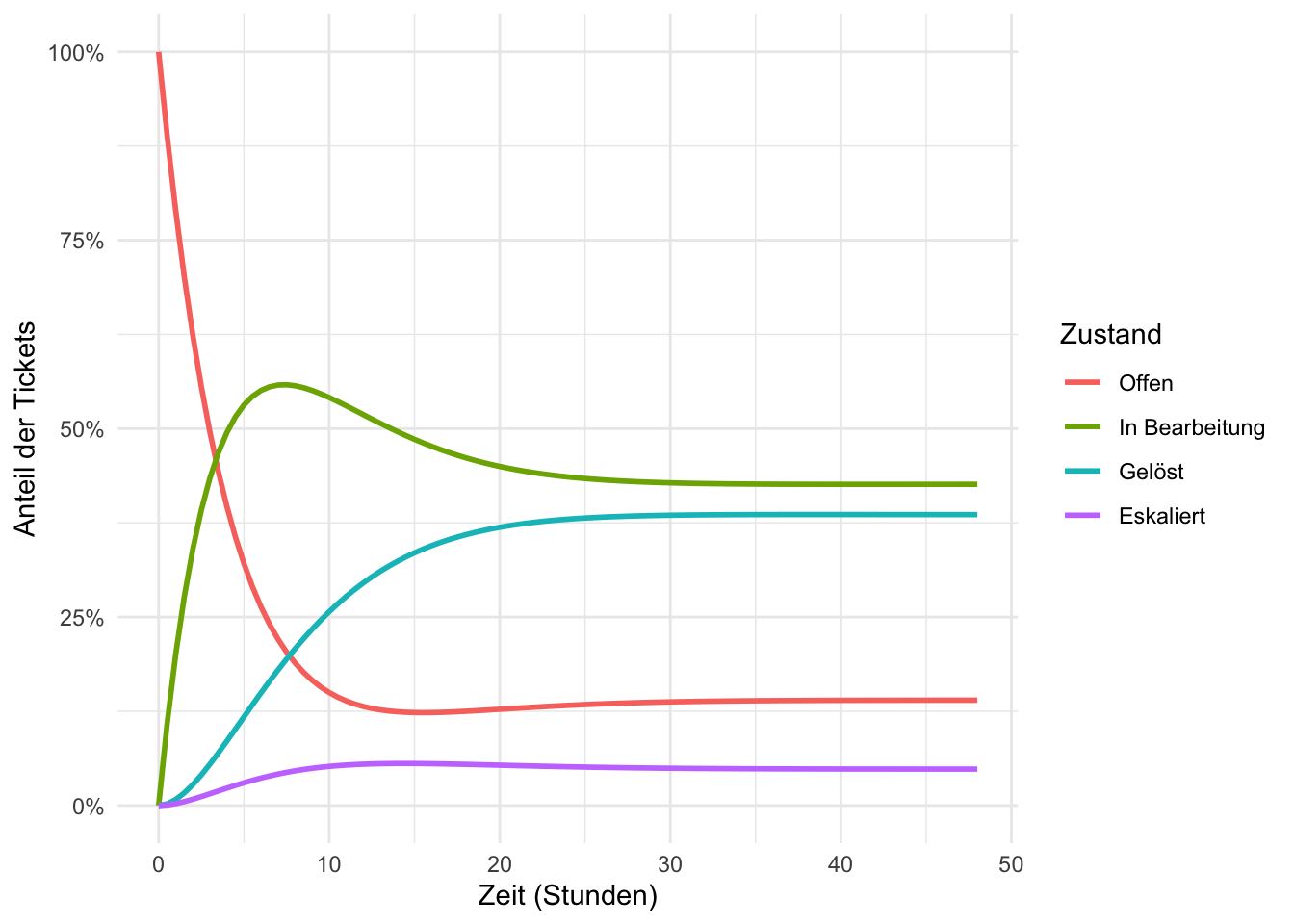
Abbildung 2: Entwicklung der Zustandsverteilung über 14 Schritte. Jede Linie zeigt den Anteil der Tickets in einem Zustand.
3. Frage: Schau dir den Plot genau an. Was fällt dir auf, wenn \(t\) grösser wird? Gibt es einen Zustand, dessen Anteil sich besonders schnell stabilisiert? Und was würde das für die Teamleiterin bedeuten?
Verständnisfrage 3: Den Zustandsvektor lesen
Die Teamleiterin schaut auf n_1 — den erwarteten Bestand
von morgen. Was bedeutet der Eintrag für «Offen» in diesem Vektor?
a) Die Wahrscheinlichkeit, dass ein bestimmtes Ticket morgen offen ist.
b) Die erwartete Anzahl Tickets, die morgen im Zustand «Offen» sein werden.
c) Der Anteil der heute offenen Tickets, die morgen noch offen sind.
d) Die Wahrscheinlichkeit, dass das System morgen den Zustand «Offen» erreicht.
Antwort anzeigen
Richtige Antwort: b)n_1 wurde aus absoluten Zahlen berechnet
(n_heute enthält Anzahlen, nicht Anteile), also
enthält n_1 ebenfalls Anzahlen — die erwarteten
Ticketzahlen pro Zustand von morgen.
Antwort a) und d) wären korrekt, wenn wir mit dem
normierten Vektor q_0 gerechnet hätten.
Antwort c) beschreibt nur den Selbstübergang eines Zustands,
ignoriert aber alle Tickets, die von anderen Zuständen
nach «Offen» wechseln.
Was wir jetzt haben — und was noch fehlt
Mit dem Zustandsvektor und der Matrixmultiplikation können wir die kurzfristige und mittelfristige Frage der Teamleiterin beantworten: Wie viele Tickets sind in \(t\) Schritten in welchem Zustand?
Der Plot zeigt aber etwas Interessantes: Die Verteilung scheint sich mit wachsendem \(t\) zu stabilisieren — die Kurven laufen aufeinander zu und verändern sich immer weniger. Was ist das? Konvergiert das System immer gegen dieselbe Verteilung, egal wo wir starten? Und was bedeutet dieser Gleichgewichtszustand für die Ressourcenplanung?
Das ist die langfristige Frage — und das Thema des nächsten Kapitels.
Wohin konvergiert das System? — Stationäre Verteilung
Der Plot aus K3 zeigt es deutlich: Ab einem gewissen \(t\) ändert sich die Verteilung kaum noch. Die Anteile der Tickets in den einzelnen Zuständen pendeln sich ein.
Was bedeutet es, wenn sich \(\mathbf{q}_t\) nicht mehr verändert? Welche Bedingung müsste \(\mathbf{q}_t\) erfüllen, damit der nächste Schritt \(\mathbf{q}_{t+1} = \mathbf{q}_t \cdot P\) dieselbe Verteilung liefert wie zuvor?
Das Gleichgewicht
Wenn sich \(\mathbf{q}_t\) nicht mehr verändert, gilt:
\[\mathbf{q}_t \cdot P = \mathbf{q}_t\]
Die Verteilung bleibt beim Anwenden von \(P\) unverändert. Anschaulich gesagt: Genau so viele Tickets fliessen in jeden Zustand hinein, wie aus ihm herausfliessen.
Wir nennen eine solche Verteilung die stationäre Verteilung — aber bevor wir sie formal einführen, suchen wir sie zuerst für unser Helpdesk-System.
Für zwei Zustände lässt sich die Gleichgewichtsbedingung noch von Hand lösen. Mit vier Zuständen wird das schnell unübersichtlich, aber das Prinzip bleibt dasselbe: Wir suchen einen Vektor \(\boldsymbol{\pi}\), der das lineare Gleichungssystem \(\boldsymbol{\pi} \cdot P = \boldsymbol{\pi}\) erfüllt — mit der zusätzlichen Bedingung, dass die Einträge sich auf 1 summieren.
TippStationäre Verteilung
Ein Wahrscheinlichkeitsvektor \(\boldsymbol{\pi} = (\pi_1, \ldots, \pi_n)\) heisst stationäre Verteilung der Markovkette mit Übergangsmatrix \(P\), wenn gilt:
\(\pi_i\) gibt den langfristigen Anteil der Zeit an, den das System im Zustand \(i\) verbringt — unabhängig vom Startzustand.
Die stationäre Verteilung berechnen
Die Bedingung \(\boldsymbol{\pi} \cdot P = \boldsymbol{\pi}\) lässt sich umschreiben zu \(\boldsymbol{\pi} \cdot (P - I) = \mathbf{0}\). Transponiert ergibt das ein lineares Gleichungssystem, das wir mit solve() lösen — nachdem wir eine der Gleichungen durch die Normierungsbedingung ersetzen:
Tabelle 4: Erwarteter Bestand im Gleichgewicht bei 340 aktiven Tickets.
Zustand
Anteil
Erwartete Anzahl
Offen
0.265
90
In Bearbeitung
0.346
118
Gelöst
0.303
103
Eskaliert
0.086
29
Die Teamleiterin liest die Tabelle und fragt: «Wie viele Agents brauche ich dauerhaft, wenn jeder Agent gleichzeitig maximal 8 Tickets «In Bearbeitung» oder «Eskaliert» betreuen kann?» Beantworte die Frage mit den Zahlen aus der Tabelle.
Konvergiert das System immer?
Bisher haben wir beobachtet, dass unser Helpdesk-System konvergiert. Aber ist das immer so?
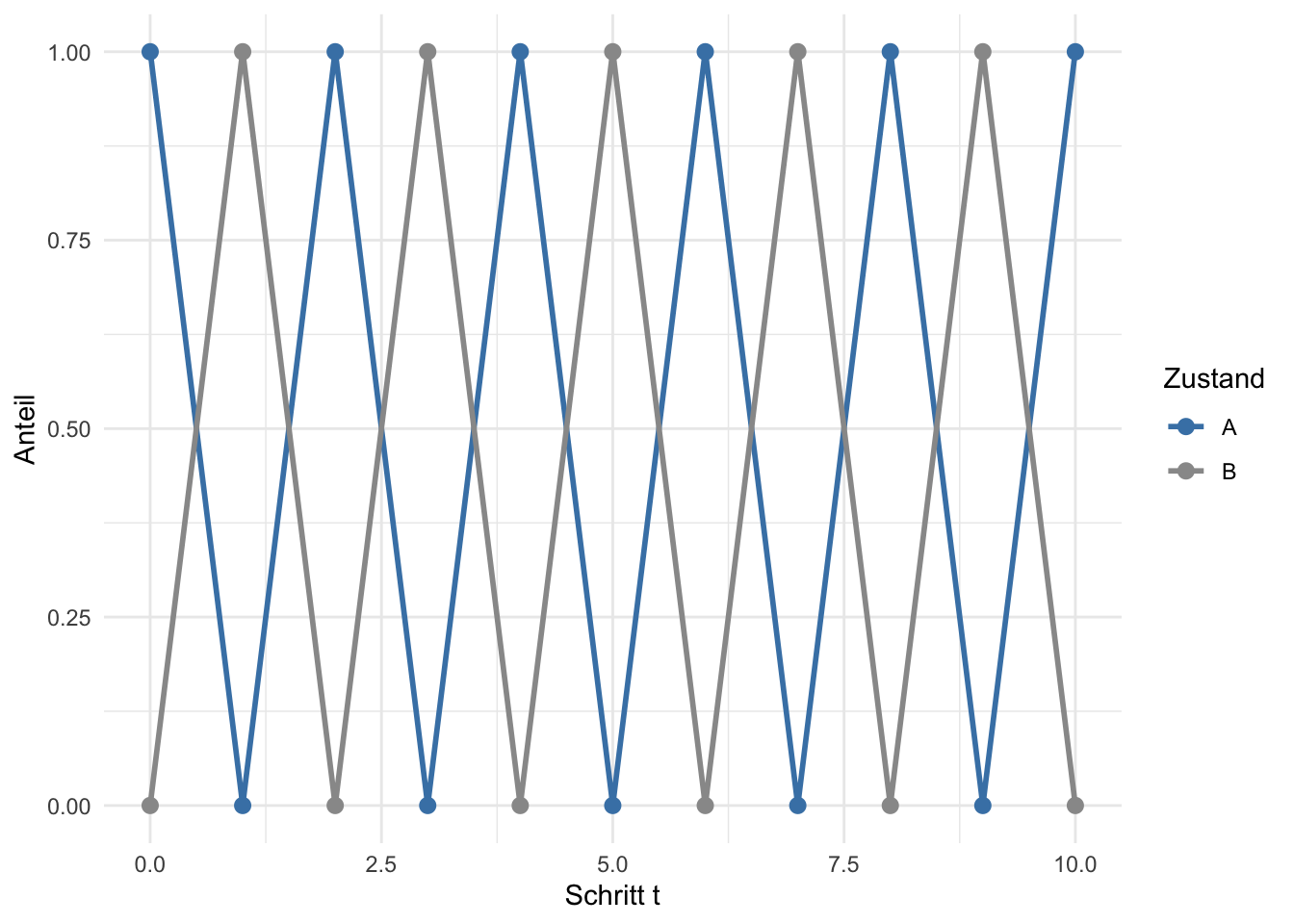
Betrachte ein einfaches Beispiel: Ein System mit zwei Zuständen \(A\) und \(B\), das in jedem Schritt deterministisch wechselt:
Abbildung 3: Ein periodisches System konvergiert nicht — es pendelt zwischen zwei Verteilungen.
Das System pendelt zwischen \((1, 0)\) und \((0, 1)\) hin und her — es konvergiert nie. Schuld ist die Periode: Von \(A\) aus gelangt man nur nach einer geraden Anzahl Schritte zurück zu \(A\). Man nennt dieses System periodisch (Periode 2).
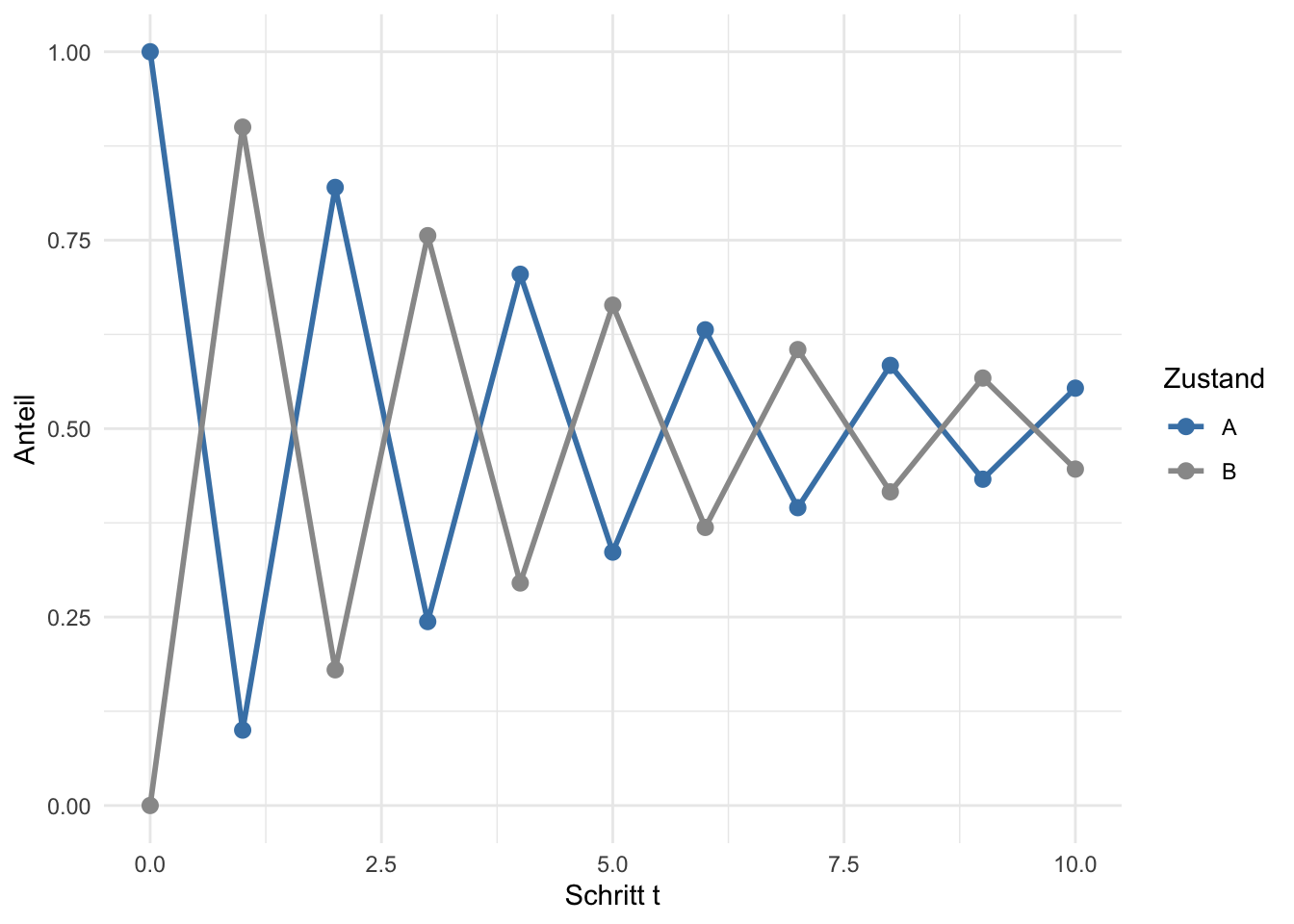
Fügt man einen kleinen Selbstübergang hinzu — das System verweilt gelegentlich im aktuellen Zustand — bricht die starre Periode auf:
Abbildung 4: Dieselbe Kette mit Selbstübergängen (p = 0.1): aperiodisch, konvergiert zur stationären Verteilung.
Neben der Aperiodizität braucht man eine zweite Eigenschaft: Irreduzibilität — jeder Zustand muss von jedem anderen aus erreichbar sein. Eine Kette, bei der ein Zustand nicht verlassen werden kann, würde ebenfalls nicht konvergieren.
TippErgodische Markovkette
Eine endliche Markovkette heisst ergodisch, wenn sie irreduzibel (jeder Zustand von jedem anderen erreichbar) und aperiodisch (keine starre Periode) ist.
Für ergodische Markovketten gilt: \[\lim_{t \to \infty} \mathbf{q}_t = \boldsymbol{\pi}
\quad \text{unabhängig von } \mathbf{q}_0\]
Die stationäre Verteilung \(\boldsymbol{\pi}\) ist eindeutig und wird unabhängig vom Startpunkt erreicht.
Unser Helpdesk-System ist ergodisch: Jeder Zustand ist von jedem anderen erreichbar, und die Zykluslängen haben keinen gemeinsamen Teiler grösser als 1 — das lässt sich am Übergangsdiagramm aus K2 direkt ablesen.
Verständnisfrage 4: Die stationäre Verteilung interpretieren
Die stationäre Verteilung des Helpdesks ergibt
π["Gelöst"] ≈ 0.52.
Was bedeutet das konkret?
a) 52 % aller Tickets werden im ersten Schritt gelöst.
b) Im Gleichgewicht sind dauerhaft etwa 52 % der aktiven
Tickets im Zustand «Gelöst».
c) Die Wahrscheinlichkeit, dass ein bestimmtes Ticket
irgendwann gelöst wird, beträgt 52 %.
d) Nach 52 Schritten hat jedes Ticket den Zustand «Gelöst»
mindestens einmal besucht.
Antwort anzeigen
Richtige Antwort: b)
Die stationäre Verteilung beschreibt den langfristigen
Gleichgewichtszustand — nicht einen einzelnen Übergang
(Antwort a) und nicht die Gesamtwahrscheinlichkeit einer
Erreichbarkeit (Antwort c).
Antwort d) macht eine Aussage über Übergangszeiten,
nicht über die stationäre Verteilung.
Was wir jetzt haben — und was noch fehlt
Wir können alle drei Fragen der Teamleiterin beantworten: kurzfristig mit \(\mathbf{q}_t = \mathbf{q}_0 \cdot P^t\), langfristig mit \(\boldsymbol{\pi}\).
Das Modell hat aber eine stille Annahme getragen: Zeit ist diskret — ein Schritt entspricht einem Ereignis. In der Realität passieren Zustandswechsel zu beliebigen Zeitpunkten. Die Frage «Wie lange liegt ein Ticket im Schnitt im Zustand Eskaliert?» lässt sich mit dem bisherigen Modell nicht direkt beantworten.
Dafür brauchen wir Markovketten mit kontinuierlicher Zeit — und das ist das Thema des nächsten Kapitels.
Wie lange dauert es? — Kontinuierliche Markovketten
Das diskrete Modell aus K2–K4 beschreibt was passiert: Welcher Zustand folgt auf welchen, und mit welcher Wahrscheinlichkeit. Was es nicht beschreibt: Wie lange ein Ticket in einem Zustand verweilt.
Die Logs enthalten Zeitstempel — diese Information haben wir bisher ignoriert. Dabei steckt darin genau das, was die Teamleiterin noch wissen will:
Wie lange liegt ein Ticket im Schnitt im Zustand «Eskaliert», bevor etwas passiert? Und wenn zehn eskalierte Tickets gleichzeitig auf eine Lösung warten — wie viel Kapazität bindet das im Durchschnitt?
Was fehlt — und was die Zeitstempel verraten
Wir schauen uns an, wie lange Tickets tatsächlich in den einzelnen Zuständen verweilen. Aus dem Log lässt sich die Verweildauer für jeden Zustandsaufenthalt direkt ablesen — als Differenz zweier aufeinanderfolgender Zeitstempel:
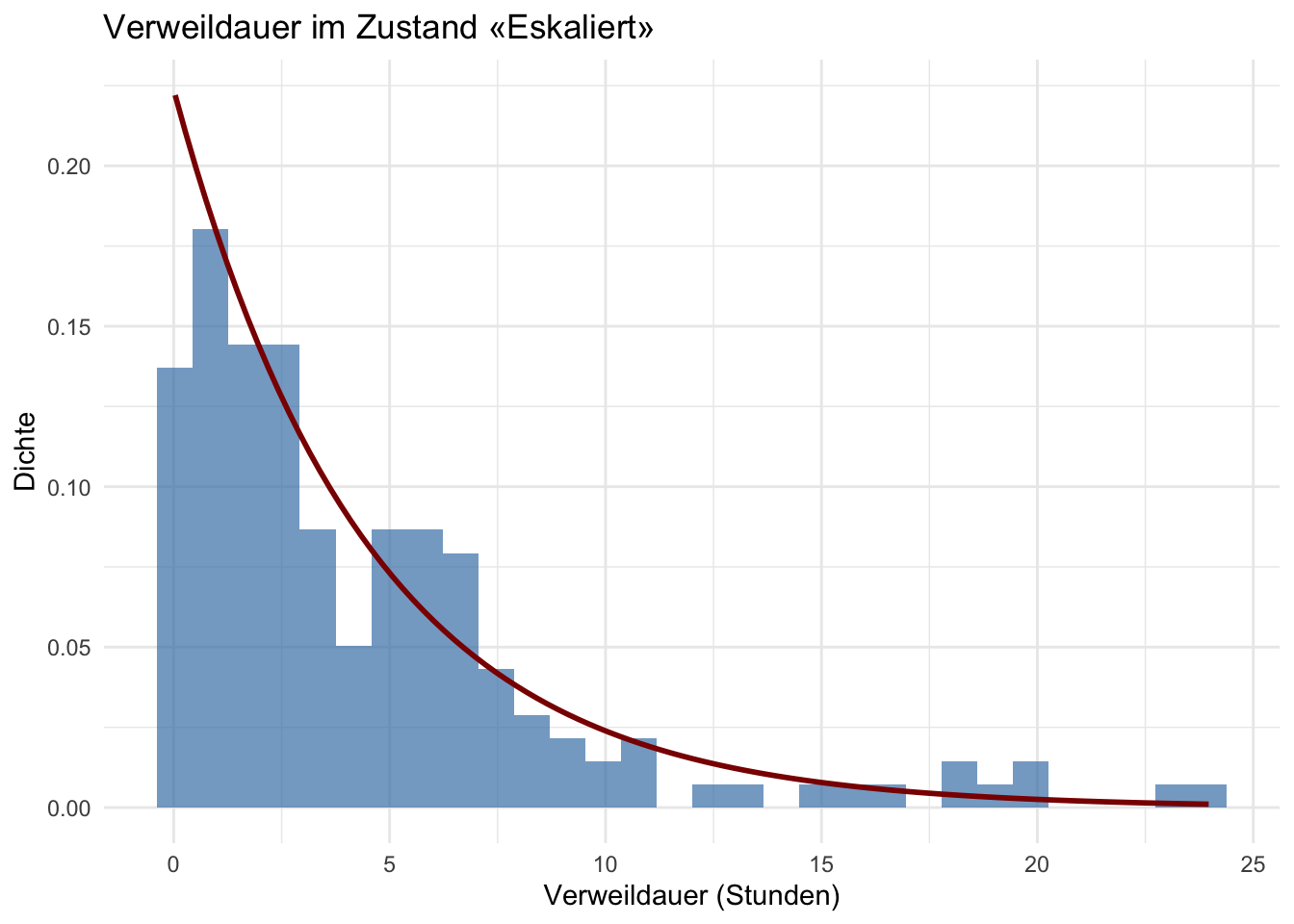
Ein eskaliertes Ticket verweilt im Schnitt 4.5 Stunden, bevor sich etwas tut — damit lässt sich planen.
Welche Verteilung würdest du für die Verweildauer in einem Zustand erwarten — also für die Zeit, bis das nächste Ereignis eintritt? Denk dabei an eine Eigenschaft, die wir bereits aus K1 kennen: Der nächste Zustand hängt nur vom aktuellen ab — nicht davon, wie lange das Ticket schon dort ist.
Die Exponentialverteilung als natürliche Wartezeit
Die Markov-Eigenschaft gilt auch in der Zeit: Wie lange ein Ticket noch in «Eskaliert» bleibt, hängt nicht davon ab, wie lange es schon dort ist. Auf Deutsch: die Verweildauer ist gedächtnislos.
Die einzige stetige Verteilung mit dieser Eigenschaft ist die Exponentialverteilung. Sie beschreibt die Zeit bis zum nächsten Ereignis mit einer konstanten Rate \(\lambda\) — je grösser \(\lambda\), desto kürzer die mittlere Wartezeit:
Abbildung 5: Verteilung der Verweildauer in ‘Eskaliert’. Die eingezeichnete Kurve ist eine angepasste Exponentialverteilung.
Von Verweildauern zu Übergangsraten
Wenn ein Ticket im Zustand \(i\) im Schnitt \(E[T_i]\) Stunden verweilt und dann in den Zustand \(j\) wechselt, dann wechselt es mit der Rate
\[q_{ij} = \frac{p_{ij}}{E[T_i]}\]
Dabei ist \(p_{ij}\) die Übergangswahrscheinlichkeit aus der diskreten Matrix \(P\) — sie gibt an, wohin das Ticket beim nächsten Ereignis geht. Die Rate \(q_{ij}\) gibt an, wie schnell dieser Wechsel im Mittel passiert.
Wir berechnen zunächst die mittleren Verweildauern pro Zustand und leiten daraus alle Raten ab:
Abbildung 6: Zeitliche Entwicklung der Zustandsverteilung in der kontinuierlichen Kette (Startpunkt: alle Tickets offen).
Stationäre Verteilung der kontinuierlichen Kette
Für die kontinuierliche Kette gilt im Gleichgewicht \(\boldsymbol{\pi} \cdot Q = \mathbf{0}\) statt \(\boldsymbol{\pi} \cdot P = \boldsymbol{\pi}\). Das Lösungsverfahren ist dasselbe wie in K4:
Offen In Bearbeitung Gelöst Eskaliert
0.140 0.426 0.386 0.048
4. Frage: Vergleiche \(\boldsymbol{\pi}\) der diskreten Kette (K4) mit \(\boldsymbol{\pi}\) der kontinuierlichen Kette. Stimmen sie überein — und wenn nicht, warum nicht?
Verständnisfrage 5: Generatormatrix lesen
Der Eintrag Q["Eskaliert", "In Bearbeitung"]
beträgt ca. 0.10. Was bedeutet das?
a) 10 % der eskalierten Tickets werden zurück in Bearbeitung gegeben.
b) Im Durchschnitt wechselt ein eskaliertes Ticket 0.10-mal
pro Stunde in den Zustand «In Bearbeitung».
c) Ein Ticket braucht im Schnitt 10 Stunden, um von «Eskaliert»
nach «In Bearbeitung» zu wechseln.
d) Die Wahrscheinlichkeit, dass ein eskaliertes Ticket
als nächstes «In Bearbeitung» wird, beträgt 10 %.
Antwort anzeigen
Richtige Antwort: b) und c)
sind beide korrekt — sie sagen dasselbe auf zwei Arten.
Eine Rate von 0.10 pro Stunde bedeutet im Schnitt einen solchen
Übergang alle $1/0.10 = 10$ Stunden.
Antwort a) beschreibt die Übergangswahrscheinlichkeit $p_{ij}$
aus der diskreten Matrix $P$, nicht die Rate.
Antwort d) verwechselt ebenfalls Rate mit Wahrscheinlichkeit.
Was wir jetzt haben — und was noch fehlt
Wir haben das Modell von diskreten Ereignissen zu kontinuierlicher Zeit erweitert — und können jetzt Fragen über Verweildauern und zeitliche Entwicklung beantworten.
Ein wichtiges Anwendungsgebiet kontinuierlicher Markovketten sind Warteschlangen: Tickets treffen mit einer bestimmten Rate ein, Agents bearbeiten sie mit einer bestimmten Rate. Wann kollabiert das System? Wie lang ist die mittlere Wartezeit eines Tickets, bis es überhaupt angeschaut wird?
Das ist das Thema des letzten Kapitels.
Wann kollabiert der Helpdesk? — Warteschlangen und M/M/1
Die Teamleiterin hat jetzt ein vollständiges Bild des laufenden Betriebs. Aber nächsten Monat rollt die IT-Abteilung ein neues ERP-System aus — erfahrungsgemäss verdoppelt sich das Ticketaufkommen in den ersten Wochen.
Das Ticketaufkommen steigt. Ab welchem Punkt reicht die Bearbeitungskapazität nicht mehr aus — und wie lang werden die Wartezeiten, bevor ein Agent überhaupt mit einem Ticket anfängt?
Das System als Warteschlange
Bisher haben wir Tickets einzeln durch die Zustände verfolgt. Jetzt wechseln wir die Perspektive: Wir schauen auf den Helpdesk als Ganzes und fragen, wie viele Tickets sich zu einem Zeitpunkt im System befinden.
Der Zustand des Systems ist jetzt die Anzahl der Tickets — wartende plus in Bearbeitung befindliche zusammen. Tickets kommen mit einer konstanten Rate \(\lambda\) an, und ein Agent bearbeitet sie mit Rate \(\mu\).
Das klingt vertraut: Ein System springt zwischen Zuständen, der nächste Zustand hängt nur vom aktuellen ab, Übergänge passieren zu zufälligen Zeiten. Was ist das?
Genau — das ist eine kontinuierliche Markovkette, wie wir sie in K5 kennengelernt haben. Nur dass der Zustandsraum jetzt unendlich ist: \(S = \{0, 1, 2, 3, \ldots\}\).
Die Übergangsraten sind einfach: - Aus Zustand \(k\) nach \(k+1\): Rate \(\lambda\) (ein neues Ticket kommt an) - Aus Zustand \(k\) nach \(k-1\): Rate \(\mu\) (ein Ticket wird abgeschlossen, falls \(k \geq 1\))
Diese Struktur heisst Birth-and-Death-Prozess — und die Generatormatrix \(Q\) sieht für die ersten paar Zustände so aus:
Wir suchen \(\boldsymbol{\pi}\) mit \(\boldsymbol{\pi} \cdot Q = \mathbf{0}\). Für Birth-and-Death-Prozesse geht das elegant: Im Gleichgewicht muss für jeden Schnitt zwischen Zustand \(k\) und \(k+1\) gelten, dass der Fluss in beide Richtungen gleich gross ist:
Ein System mit Poisson-Ankünften (Rate \(\lambda\)), exponentiellen Bearbeitungszeiten (Rate \(\mu\)) und einem Server heisst M/M/1-Warteschlange.
Für \(\rho = \lambda/\mu < 1\) existiert eine stationäre Verteilung: \[\pi_k = (1-\rho)\,\rho^k, \quad k = 0, 1, 2, \ldots\]
Die wichtigsten Kennzahlen im Gleichgewicht:
Grösse
Formel
Bedeutung
\(\rho\)
\(\lambda/\mu\)
Auslastung des Servers
\(E[N]\)
\(\rho/(1-\rho)\)
Mittlere Anzahl im System
\(E[R]\)
\(1/(\mu-\lambda)\)
Mittlere Antwortzeit
\(E[W]\)
\(\rho/(\mu-\lambda)\)
Mittlere Wartezeit
Für \(\rho \geq 1\) wächst die Schlange unbegrenzt — das System kollabiert.
Die Formel von Little
Zwischen \(E[N]\) und \(E[R]\) besteht ein eleganter Zusammenhang, der für jedes stabile Warteschlangensystem gilt — unabhängig von der Verteilung der Ankunfts- oder Bearbeitungszeiten:
\[E[N] = \lambda \cdot E[R]\]
Anschaulich: Wenn \(\lambda = 2\) Tickets pro Stunde ankommen und jedes im Schnitt \(E[R] = 3\) Stunden im System verbringt, sind im Schnitt \(2 \times 3 = 6\) Tickets gleichzeitig im System. Diese Beziehung heisst Formel von Little.
Der Helpdesk unter Last
Für den Normalbetrieb schätzt die Teamleiterin: \(\lambda = 1/3\) Ticket pro Stunde, \(\mu = 1/2\) Ticket pro Stunde.
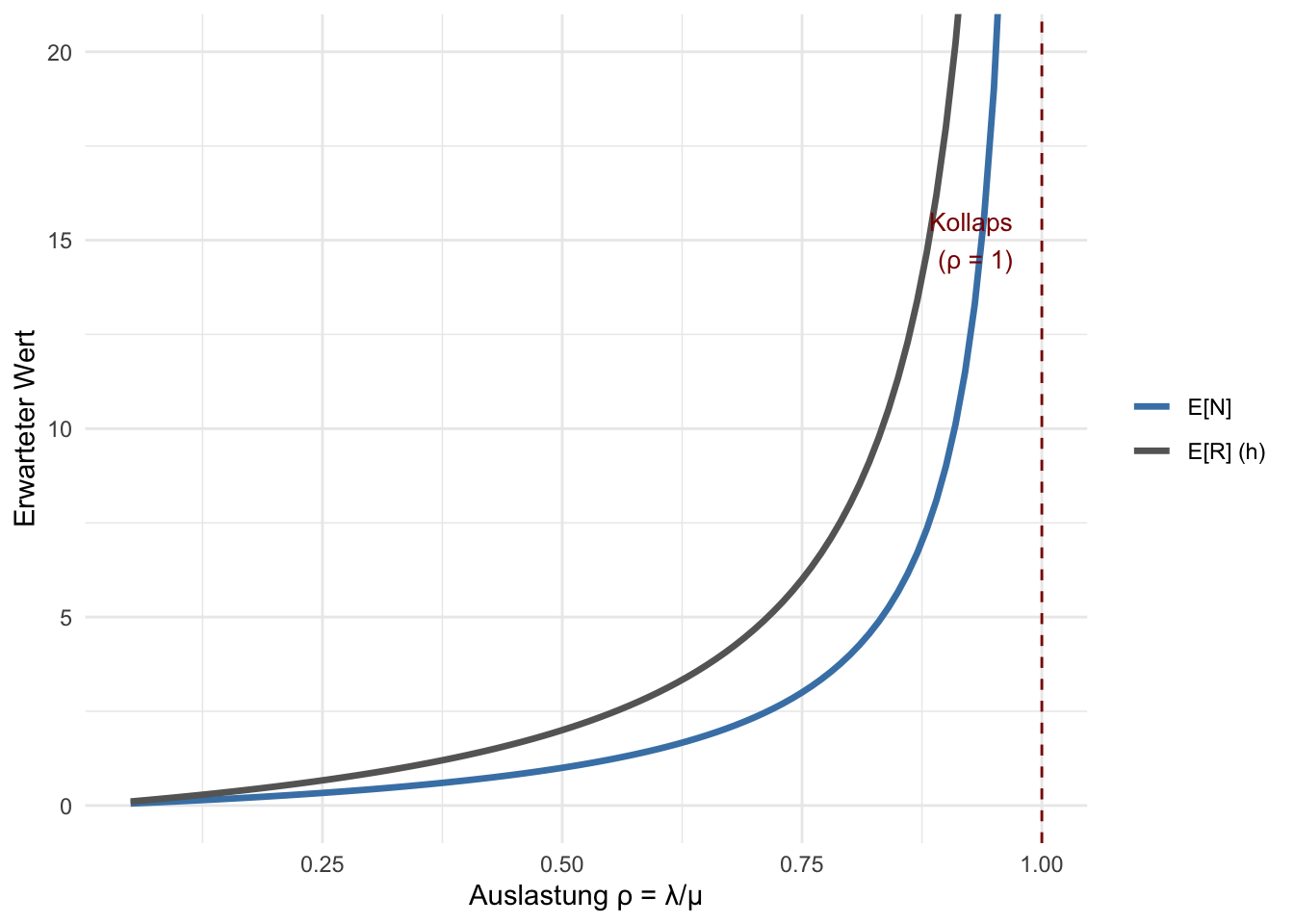
Abbildung 7: Mittlere Antwortzeit E[R] und mittlere Systemgrösse E[N] als Funktion der Auslastung ρ. Beide divergieren, wenn ρ → 1.
Der Plot zeigt: Das System verhält sich lange gutartig — aber nahe \(\rho = 1\) explodieren sowohl Warteschlange als auch Wartezeit. Die Antwort auf die Ausgangsfrage ist damit präzise: Bei \(\rho \geq 1\) reicht ein Agent nicht mehr aus. Im Rollout-Szenario (\(\rho \approx 0.89\)) sind die Wartezeiten bereits kritisch — die Teamleiterin braucht Verstärkung, bevor das System kollabiert, nicht danach.
Verständnisfrage 6: Die Formel von Little
Im Normalbetrieb kommen $\lambda = 1/3$ Tickets pro Stunde an.
Die mittlere Antwortzeit beträgt $E[R] = 6$ Stunden.
Wie viele Tickets sind im Schnitt gleichzeitig im System?
a) 2 Tickets
b) 6 Tickets
c) 18 Tickets
d) Das lässt sich ohne μ nicht berechnen.
Antwort anzeigen
Richtige Antwort: a)
Die Formel von Little: $E[N] = \lambda \cdot E[R]
= \frac{1}{3} \cdot 6 = 2$.
Sie braucht nur $\lambda$ und $E[R]$ — $\mu$ ist nicht erforderlich.
Das ist der Witz von Littles Gesetz: Es gilt für beliebige
stabile Systeme, unabhängig von der konkreten Verteilung
der Ankunfts- oder Bedienzeiten.
Drei Fragen — drei Antworten
Am Anfang von K2 hat die Teamleiterin drei Fragen gestellt. Jetzt haben wir das Werkzeug für alle drei:
Frage
Werkzeug
Kapitel
Wie viele Tickets sind morgen offen?
\(\mathbf{q}_t = \mathbf{q}_0 \cdot P^t\)
K3
Wohin konvergiert das System langfristig?
Stationäre Verteilung \(\boldsymbol{\pi}\)
K4
Wann kollabiert der Helpdesk unter Last?
M/M/1: \(E[R] = 1/(\mu - \lambda)\), Formel von Little
K6
Alle drei Antworten kommen aus demselben Fundament: der Markov-Eigenschaft aus K1 und der Übergangsmatrix aus K2.
Quellcode
---title: "Markovketten"subtitle: "Von der Ticket-Warteschlange zur stationären Verteilung"author: - name: "Markus Geuss" affiliation: "Fernfachhochschule Schweiz"title-block-banner: ./images/ffhs-farbwelt-verlauf_01.jpglang: delanguage: de: author-meta-affiliation: "Hochschule"format: html: logo: ./images/FFHS_Logo.png include-in-header: text: | <style> .title { color: white !important; } .subtitle { color: white !important; } .quarto-title-banner .quarto-title { padding-left: 160px; } </style> <script> document.addEventListener('DOMContentLoaded', function () { var banner = document.querySelector('.quarto-title-banner'); if (banner) { banner.style.position = 'relative'; var logo = document.createElement('img'); logo.src = './images/FFHS_Logo.png'; logo.style.cssText = [ 'position: absolute', 'left: 0px', 'top: 50%', 'transform: translateY(-50%)', 'height: 75px', 'width: auto', 'z-index: 10', 'filter: brightness(0) invert(1)' ].join(';'); banner.insertBefore(logo, banner.firstChild); } }); </script> theme: cosmo toc: true toc-title: "Inhaltsverzeichnis" toc-depth: 3 toc-location: right code-fold: true code-tools: true self-contained: falseexecute: warning: false message: falseeditor: markdown: wrap: sentence---```{r}#| label: setup#| include: falselibrary(tidyverse)library(igraph)library(matrixcalc)library(expm)```{{< include kapitel/K0_Lernziele.qmd >}}{{< include kapitel/K1_StochastischeProzesse.qmd >}}{{< include kapitel/K2_Uebergangsmatrix.qmd >}}{{< include kapitel/K3_Zustandsvektoren.qmd >}}{{< include kapitel/K4_StationaereVerteilung.qmd >}}{{< include kapitel/K5_KontinuierlicheMK.qmd >}}{{< include kapitel/K6_Warteschlangen.qmd >}}